概述
Facebook Velox 是一个针对 SQL 运行时的 C++ 库,旨在统一 Facebook 各种计算流,包括 Spark 和 Presto,使用推的模式、支持向量计算。
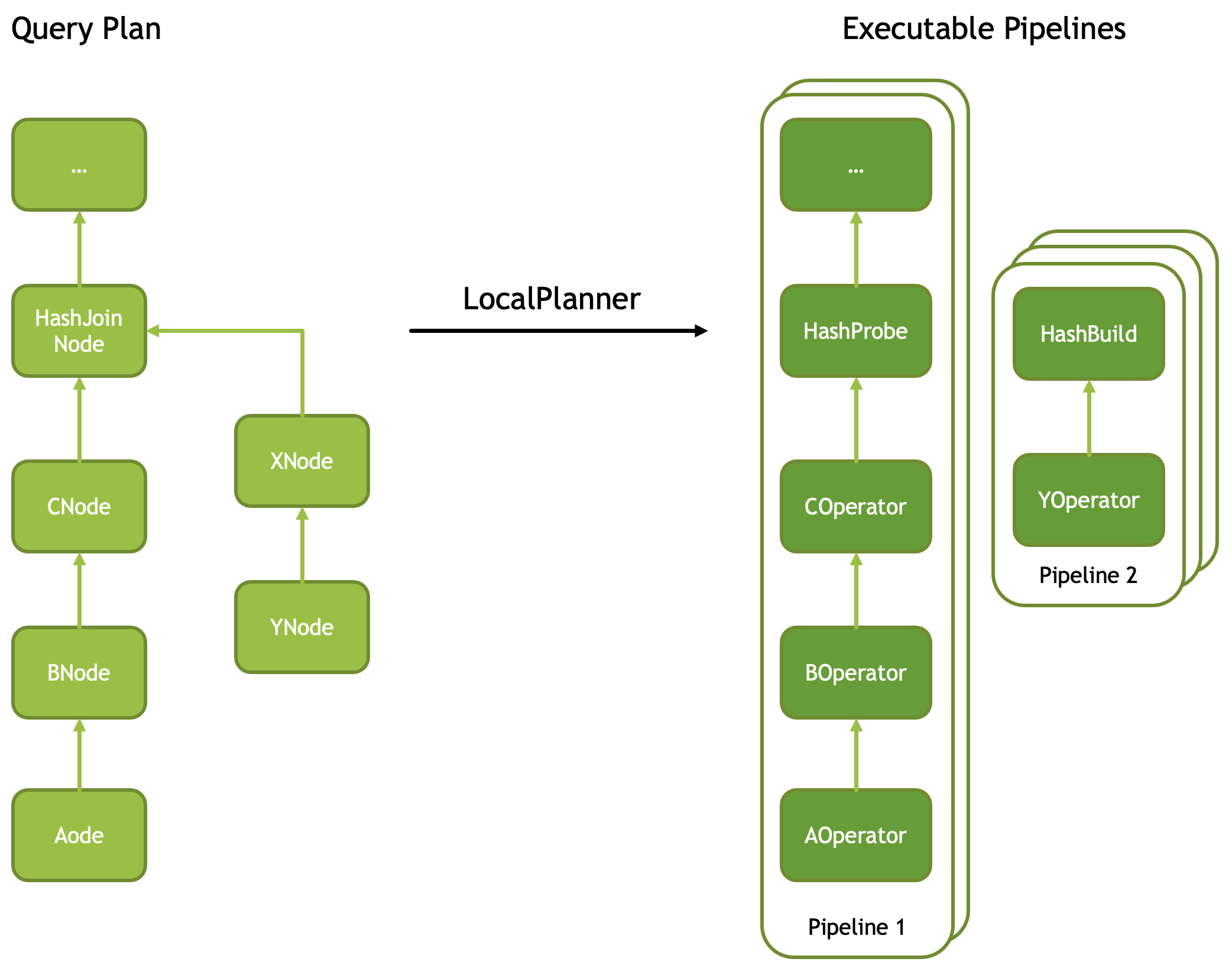
Velox 接受一棵优化过的 PlanNode Tree,然后将其切成一个个的线性的 Pipeline,Task 负责这个转变过程,每个 Task 针对一个 PlanTree Segment。大多数算子是一对一翻译的,但是有一些特殊的算子,通常出现在多个 Pipeline 的切口处,通常来说,这些切口对应计划树的分叉处,如 HashJoinNode,CrossJoinNode, MergeJoinNode ,通常会翻译成 XXProbe 和 XXBuild。但也有一些例外,比如 LocalPartitionNode 和 LocalMergeNode 。
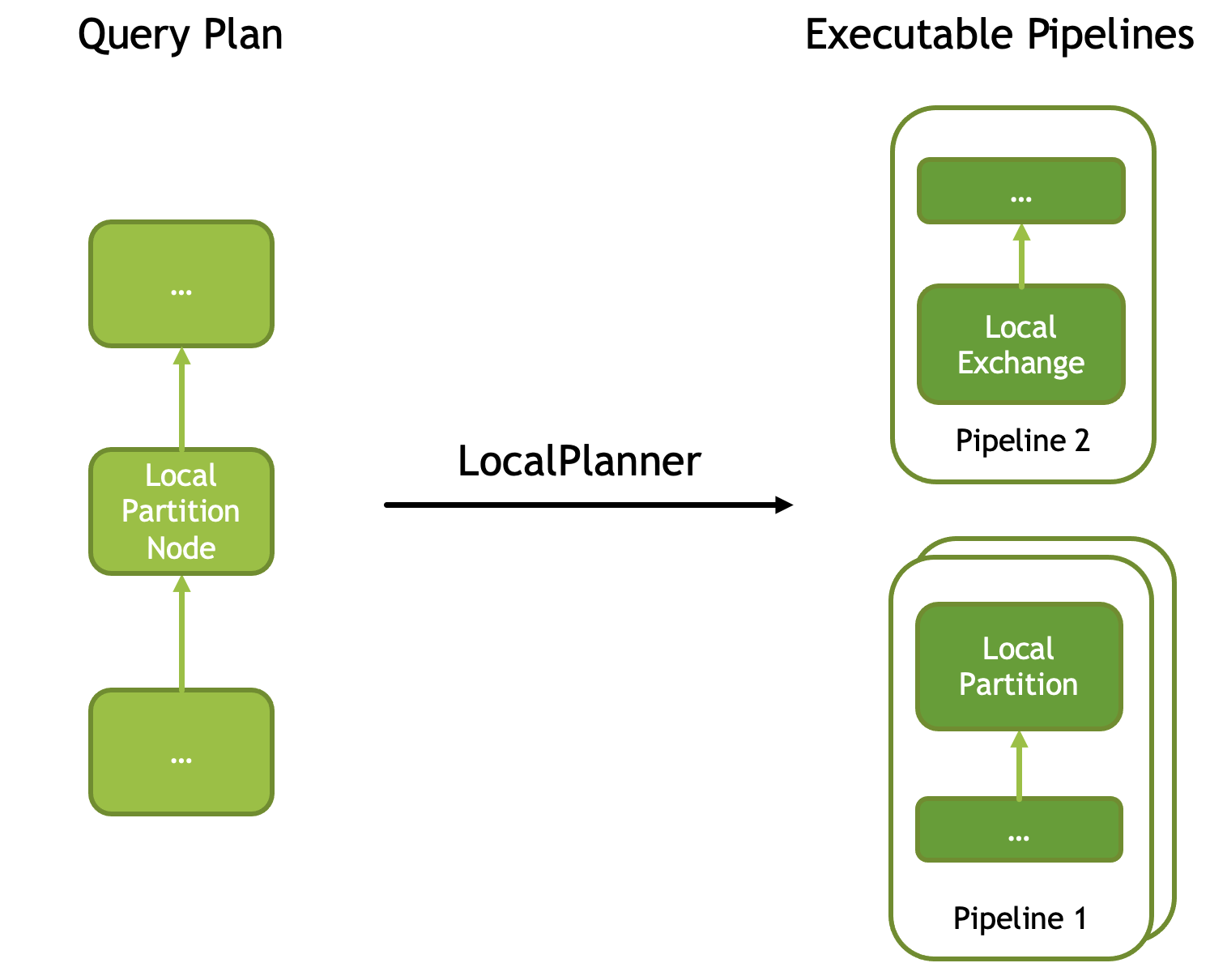
为了提高执行的并行度,Velox 引入了 LocalPartitionNode 节点,可以将一个 Pipeline 进行多线程(每个线程一个实例)并行运行,并且互斥的消费数据。其中每个实例称为 Driver。该算子在输入计划树里并没有分叉(即没有多个 source),但在翻译成物理算子时,会在此节点处进行切开,并在切口前后改变执行的并行度,对应的物理算子是LocalPartition 和 LocalExchange。
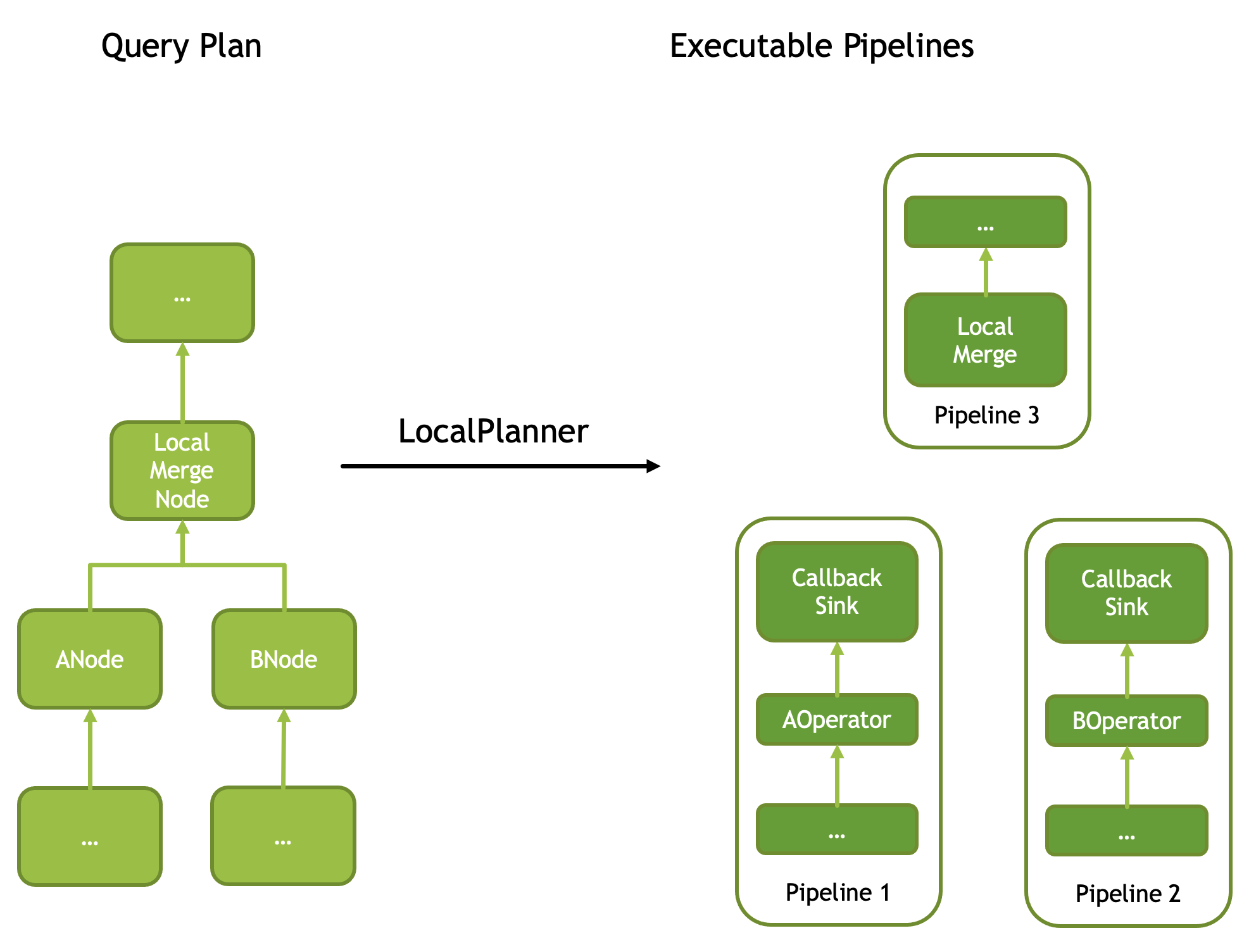
还有一个特殊节点,称为 LocalMergeNode,该对输入有要求:必须有序,然后会进行单线程的归并排序,从而使输出全局有序。也因此,由其而切开的消费 Pipeline 一定是单 Driver 的。翻译成算子,对应两个 CallbackSink 和 LocalMerge。
总结一下,上述五个 PlanNode,HashJoinNode,CrossJoinNode, MergeJoinNode ,LocalPartitionNode ,LocalMergeNode 在翻译时会造成切口,即将逻辑 PlanTree 切成多个物理 Pipeline,因此在切口处会将一个逻辑算子翻译成多个物理算子,分到不同 Pipeline 上。每个 Pipeline 会有一个从 0 开始的编号:Pipeline ID,是全局粒度的。
并且,可以由 LocalPartitionNode 来按需改变每个 Pipeline 并行度,其中 Pipeline 的每个线程由一个 Driver 来执行。每个 Driver 也有一个从 0 开始的编号:Driver ID,是 Pipeline 粒度的。
其他 PlanNode 到算子的翻译基本都是一对一的,感兴趣的可以看官方文档的这个页面:Plan Nodes and Operators。
更多细节参见:https://xiaobot.net/post/ca020297-0901-45d1-8acc-1d884bf1cc84