The birth of chDB
去年在 GitHub 闲逛的时候发现了一个叫 DuckDB 的项目,当时 DuckDB 的介绍好像是“OLAP 版的 SQLite”。拿过来用了一下,感觉还挺有意思,甚至拿来做了几个小玩具。后来看到了 DuckDB 融资的新闻,着实吓了一跳:
MotherDuck Raises $47.5 Million at $175M Valuation
上个月和 Lance 社区的人 Zoom 面基聊到 DuckDB 和荷兰。整个阿姆斯特丹的数据库研究氛围非常浓郁,包括 ClickHouse 的主要作者目前都在荷兰。DuckDB 前期主要是大学里的几个人在捣鼓,后来拿到了 CWI 的科研基金。CWI 可以认为是荷兰国家的一个计算机科学和数学方向的研究基金,Python 之父 Guido 其实就是在 CWI 工作的时候创造了 Python。

荷兰 CWI
我是非常羡慕这种能大胆支持没有名气但很有料的国家基金的,希望国内后面也能有一些这种基金。杂家毫不负责的说,早期可以把漂亮国政府实体名单认证的公司先投个遍。
临渊羡鱼,不如退而结网
在正式开始 chDB 的旅程之前,我觉得最好先简单介绍一下 ClickHouse。前几年 OLAP 数据库圈子里特别流行"向量化引擎",主要原因应该是 CPU 越来越多的 SIMD 指令集的加入,让 OLAP 这种场景下大量数据的 Aggregation、Sort、Join 加速效果十分明显。ClickHouse 在"向量化"等多个领域都做了非常深入细致的优化,可以从 ClickHouse 对 lz4 和 memcpy 的优化略见一斑。
如果说 ClickHouse 是性能最好的 OLAP 有争议,那么至少它算是第一梯队的。不说性能,ClickHouse 强大的功能也堪称数据库界的瑞士军刀:
- 直接查询 S3、GCS 等对象存储上的数据
- 使用 ReplacingMergeTree 来简化处理 Changing Data
- 不借助第三方工具,完成跨数据库的数据查询甚至 Table Join
- 甚至能自动的进行"谓词下推"(Predicate Pushdown)
开发和维护一个生产环境可用并且高效的 SQL 引擎是一个非常需要人才和时间的事情。ClickHouse 作为 OLAP 引擎中的佼佼者,Alexey Milovidov 和他的伙伴们已经持续的投入了 14 年的时间。既然 ClickHouse 已经在 SQL 引擎上做了这么多工作了,为什么不考虑一下直接把 ClickHouse 的引擎剥离出来,放到 Python 模块里。这就很有一种把火箭引擎 安装在自行车 上的感觉了。
2023 年 2 月份开始我开始开发 chDB,主要的目标是让强大的 ClickHouse 引擎可以作为 Python 的模块实现"即插即用"。ClickHouse 有一个可以独立作为命令行运行的版本 clickhouse-local,基于它 chDB 的工作显得更加有可能。
Hacking ClickHouse
其实有种非常简单粗暴的实现:直接把 clickhouse-local的二进制放到 Python 包里,然后通过类似 popen 的方式把 SQL 传给它,把结果通过一个 pipe 拿回来。
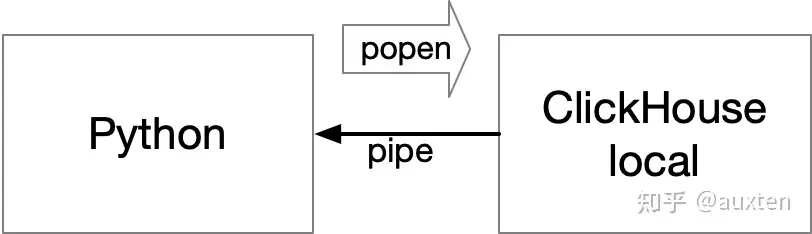
简单粗暴的实现
但是这样会带来几个额外的问题:
- 每次查询启动独立进程会很影响性能,特别是
clickhouse-local 二进制文件都是大致是 500MB 的大小的情况下
- 对 SQL 查询的结果免不了多次拷贝
- 和 Python 的结合非常受限,难以实现 Python UDF,难以支持 SQL on Pandas DataFrame。
- 最重要的是:不优雅
得益于 ClickHouse 良好的代码结构,在 90 多万行代码堆里的 Hacking 得以顺利进行,我的整个中国新年不是在吃吃喝喝就是在 Hacking ClickHouse。
ClickHouse 包含了一系列 BufferBase 的实现,包括 ReadBuffer 和 WriteBuffer 两大类,基本对应了 C++ 的 istream 和 ostream。但为了在这些 Buffer 上实现高效的文件读写和结果输出(例如读取 CSV、JSONEachRow,输出 SQL 运行的结果),ClickHouse 的 Buffer 也支持对底层内存的随机读写。甚至可以基于 vector 的内存无复制创建新的 Buffer。ClickHouse 内部的关于压缩文件的读写,远程文件(S3、HTTP)的读写都是基于 BufferBase 的衍生类。
为了在 ClickHouse 层面零复制拿到 SQL 运行的结果,我使用了内置的 WriteBufferFromVector 来替换 stdout 接收数据。这样既能保证并行输出的 Pipeline 不会阻塞又能保证比较方便的拿到 SQL 执行输出的原始内存块。
为了避免从 C++ 到 Python Object 的内存拷贝,我用了 Python 的 memoryview 来直接内存映射。
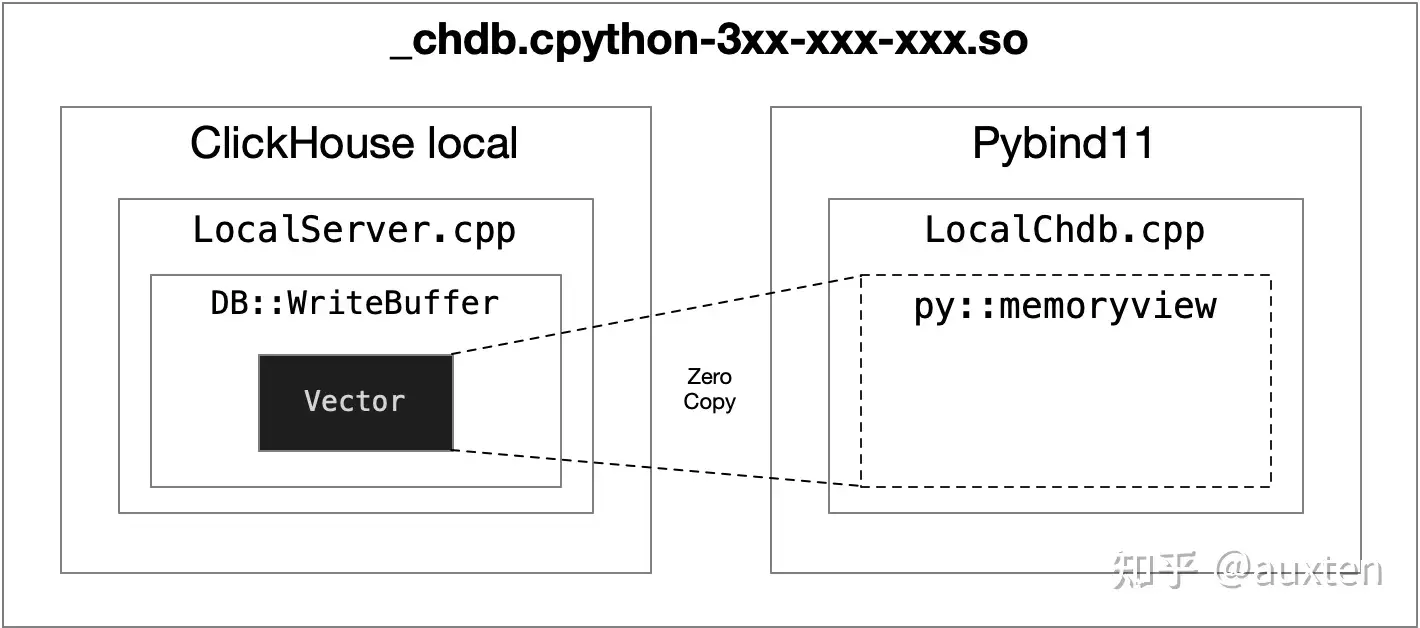
chDB 使用 memoryview 来实现 zero copy
由于 Pybind11 的成熟,C++ 的 Class 的构造和析构可以方便的和 Python Object 的生命周期绑定,这一切都只需要简单的 class template 定义:
class __attribute__((visibility("default"))) query_result {
public:
query_result(local_result * result) : result(result);
~query_result();
}
py::class_<query_result>(m, "query_result")
这样,chDB 就基本可以 run 起来了,我非常兴奋的把它发布了。chDB 的架构大致是下面这幅图:
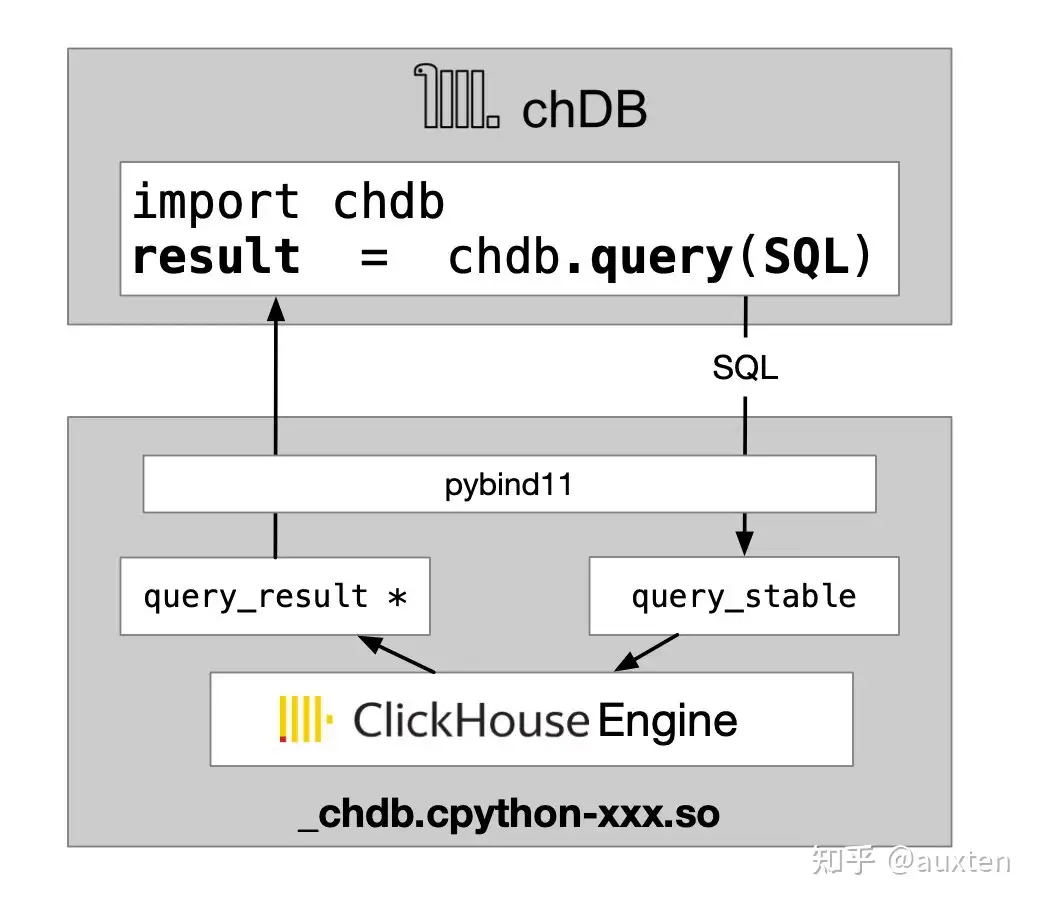
chDB 的架构
Team up
chDB 发布后,Lorenzo 很快的联系了我,他提了一个 issue: 表示如果去掉对于 AVX2 指令集的依赖可能会让 chDB 更方便的运行在 Lambda 服务上。我很快的实现了这个 feature,随后 Lorenzo 为 chDB 在 fly.io 上做了一个 Demo。坦白来讲,这样的用法是我之前从未设想过的。
chdb.fly.dev
起初我开发 chDB 只是为了做一个能够在 Jupyter Notebook 独立运行的 ClickHouse 引擎,方便我在用 Python 训练 CV 模型的时候不用访问速度缓慢的 Hive 集群去获取大量的标注信息。事实上单机版的 chDB 在大多数场景下竟然比上百台服务器组成的 Hive 运行速度要快得多。
随后 Lorenzo 和他的 team 为 chDB 开发了 Golang、NodeJS、Rust、Bun 的 Bindings。为了把这些项目都归集在一起,我在 GitHub 上建立了 chdb.io 这个组织。
随后,@laodouya 为 chDB 贡献了 Python DB API 2.0 的接口实现。@nmreadelf 为 chDB 贡献了 Dataframe output format 的支持。@https://github.com/dchimeno, @Berry, @Dan Goodman, @Sebastian Gale, @Mimoune, @schaal, @alanpaulkwan 等朋友也为 chDB 提了很多宝贵的 issues。
Jemalloc in so
chDB 在后面做了很多的性能优化工作,其中就包括了极其困难的将 jemalloc 移植到 chdb 的 so 库的工作。
在认真的分析了 chDB 在 Clickbench Q.23 Q28 上的表现后,我发现 chDB 在 Q23 下相比 clickhouse-local 有不小的性能差距。我判断 Q23 是由于 chDB 在实现的时候为了简单,剥离了 jemalloc 导致的。Let’s Fix it!
由于 ClickHouse 引擎包含了上百个 submodule,其中也包含了 Boost、LLVM 这样的重量级基础库。ClickHouse 为了保证较好的 libc、libc++ 兼容性和实现 JIT 执行引擎,链接使用的 libc 也是自带的 LLVM 中的版本。ClickHouse 的二进制可以较为容易的保证整体链接的安全性。但 chdb 作为一个 so,这部分变得异常的艰难,主要原因有以下几点:
- Python 的 Runtime 有自己的 libc,chdb.so 被加载后很多在 ClickHouse binary 中本来应该链接到 jemalloc 的内存分配&管理的相关函数会难以避免的在 @plt 连接到 Python 自带的 libc。
- 解决上述问题可以通过修改 ClickHouse 的源码,把所有相关的函数全部显式的调用
je_开头的函数,类似 je_malloc,je_free 。但这会带来两个新的问题,其中容易解决的是:
- 修改第三方库的 malloc 调用代码将会是一个非常庞大的工程,我使用的 clang++ 的链接的一个 trick:
Wl,-wrap,malloc。例如可以在链接阶段把所有调用 malloc 这个符号的调用转接到 __wrap_malloc。可以参考这里的 chDB 代码:mallocAdapt.c
事情好像被解决了,但真正的噩梦来了。chDB 还是会偶尔崩溃在一些 je_free调用上。经过不懈的排查,最终发现是一个 libc 的古老遗留问题:
在写 C 代码的时候 malloc/calloc 一般会和 free 成对的出现。我们会尽力避免在一个函数返回内部 malloc 的堆上内存。因为这样容易导致调用这个函数的人容易忘记调用 free ,从而造成内存泄露。但由于历史遗留问题,GNU libc 里有一些诸如: getcwd() 和 get_current_dir_name() 这样的函数会内部调用 malloc 分配自己的内存并返回。
而这些函数又广泛地在 STL 和 Boost 这些库里用来实现路径相关的函数。所以就会出现,getcwd 返回的是 glibc 版本的 malloc 的内存,但我们会尝试用 je_free 进行释放。So,Crash !!
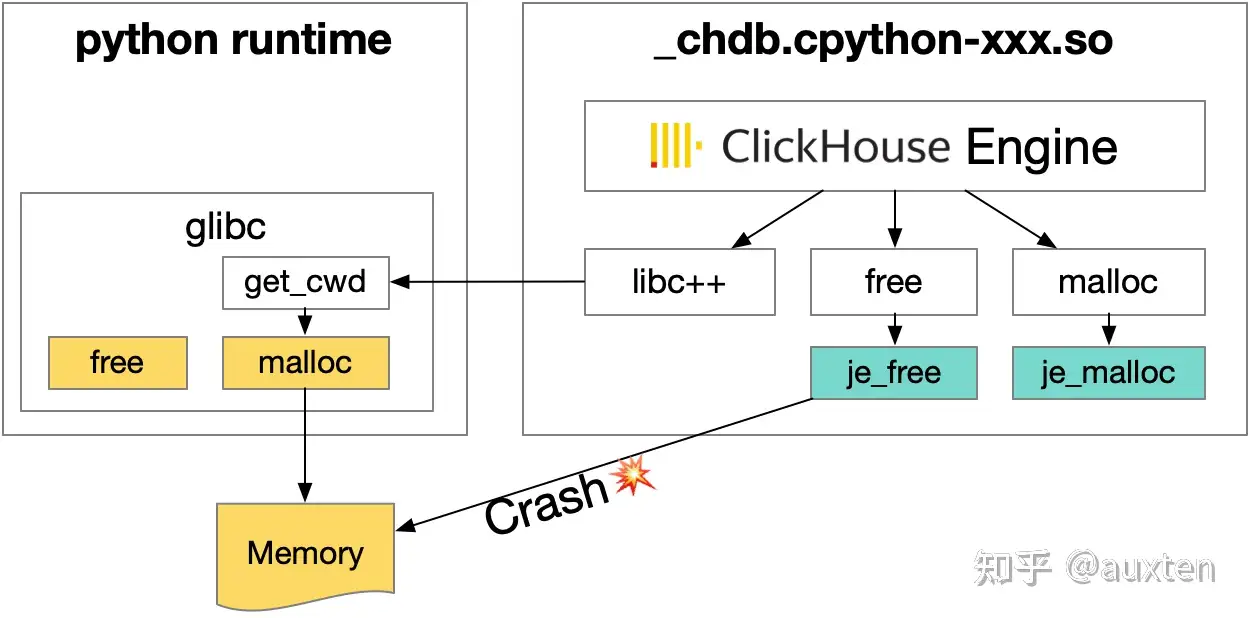
Jemalloc 导致的崩溃
如果 jemalloc 能提供一个接口查询当前指针指向的内存是否是 jemalloc 分配的,那么就好了,我们只需要在调用 je_free 之前查询一下就好了:
void __wrap_free(void * ptr)
{
int arena_ind;
if (unlikely(ptr == NULL))
{
return;
}
// in some glibc functions, the returned buffer is allocated by glibc malloc
// so we need to free it by glibc free.
// eg. getcwd, see: https://man7.org/linux/man-pages/man3/getcwd.3.html
// so we need to check if the buffer is allocated by jemalloc
// if not, we need to free it by glibc free
arena_ind = je_mallctl("arenas.lookup", NULL, NULL, &ptr, sizeof(ptr));
if (unlikely(arena_ind != 0)) {
__real_free(ptr);
return;
}
je_free(ptr);
}
但不幸的是 jemalloc 的 mallctl 虽然可以通过 arenas.lookup 来查询,但这个接口在遇到不是 jemalloc 分配的内存的情况下会 assert失败……
lookup会导致断言失败?这显然不合力嘛,于是就有了这个我提交给 jemalloc 的 patch:#2424 Make arenas_lookup_ctl triable 。目前官方已经 Merge 了这个 PR。所以,我继而又成了 jemalloc 的 contributor 。
Show time
功夫不负有心人,经过几周在 ClickHouse 和 jemalloc 上的努力,chDB 的内存占用有了大幅(50%)降低:
!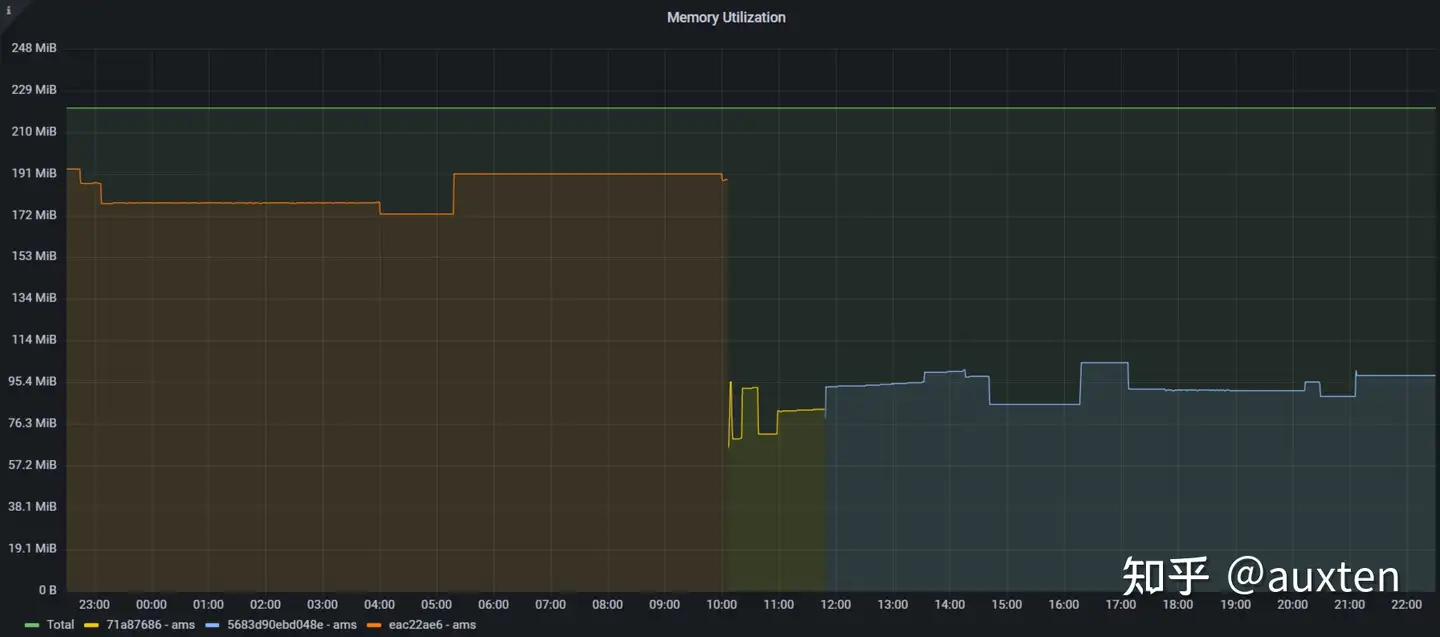
chdb metrics on fly.io
根据 ClickBench 上的数据,chDB 是目前最快的 Stateless&Serverless 数据库(不包含 ClickHouse SaaS)
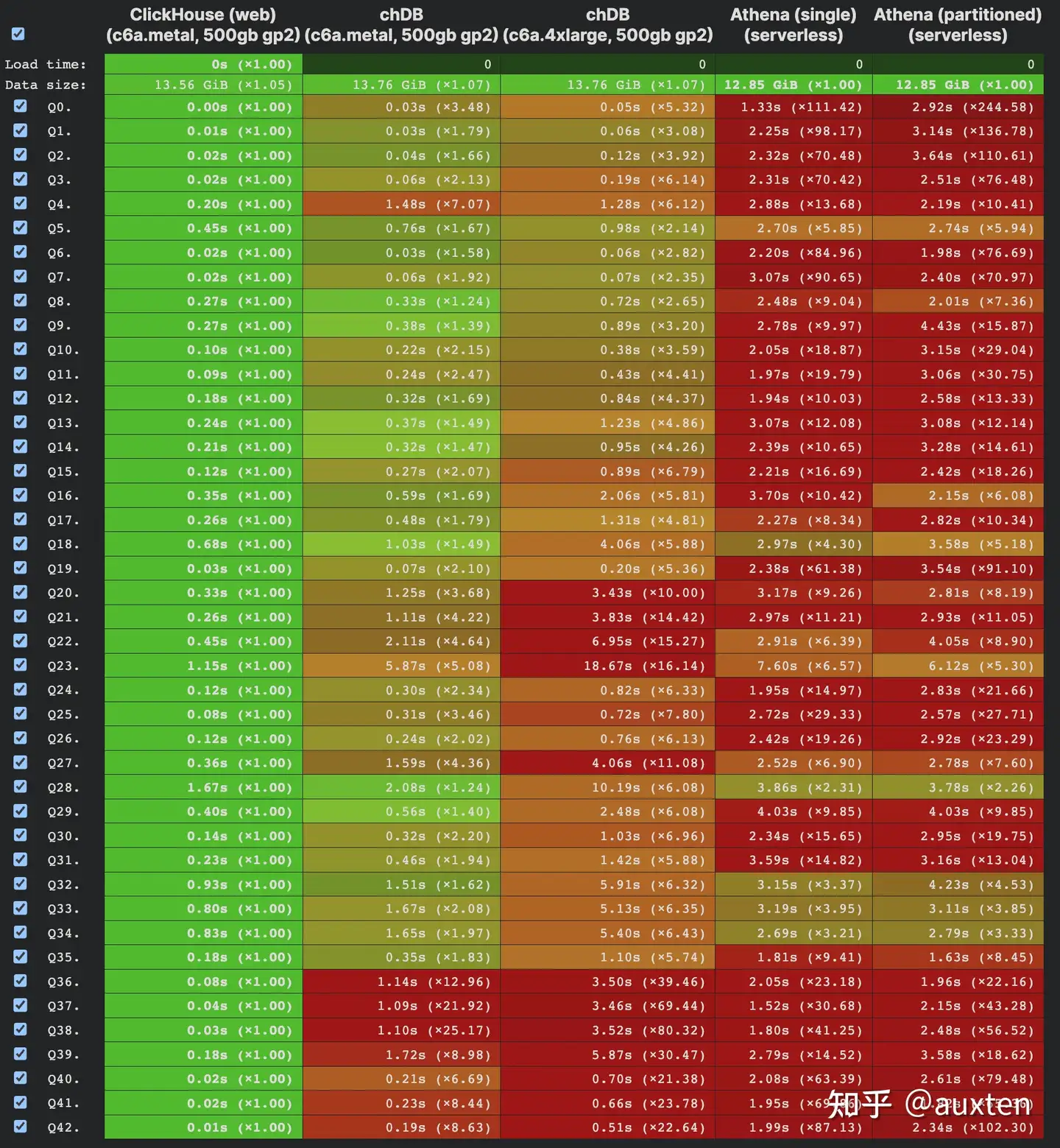
chDB 是目前最快的 Stateless&Serverless 数据库
chDB 在 SQL on Parquet 上已经是目前最快的实现(DuckDB 实际上的性能是包含了长达 142425s 的“Load” 后达成的)。
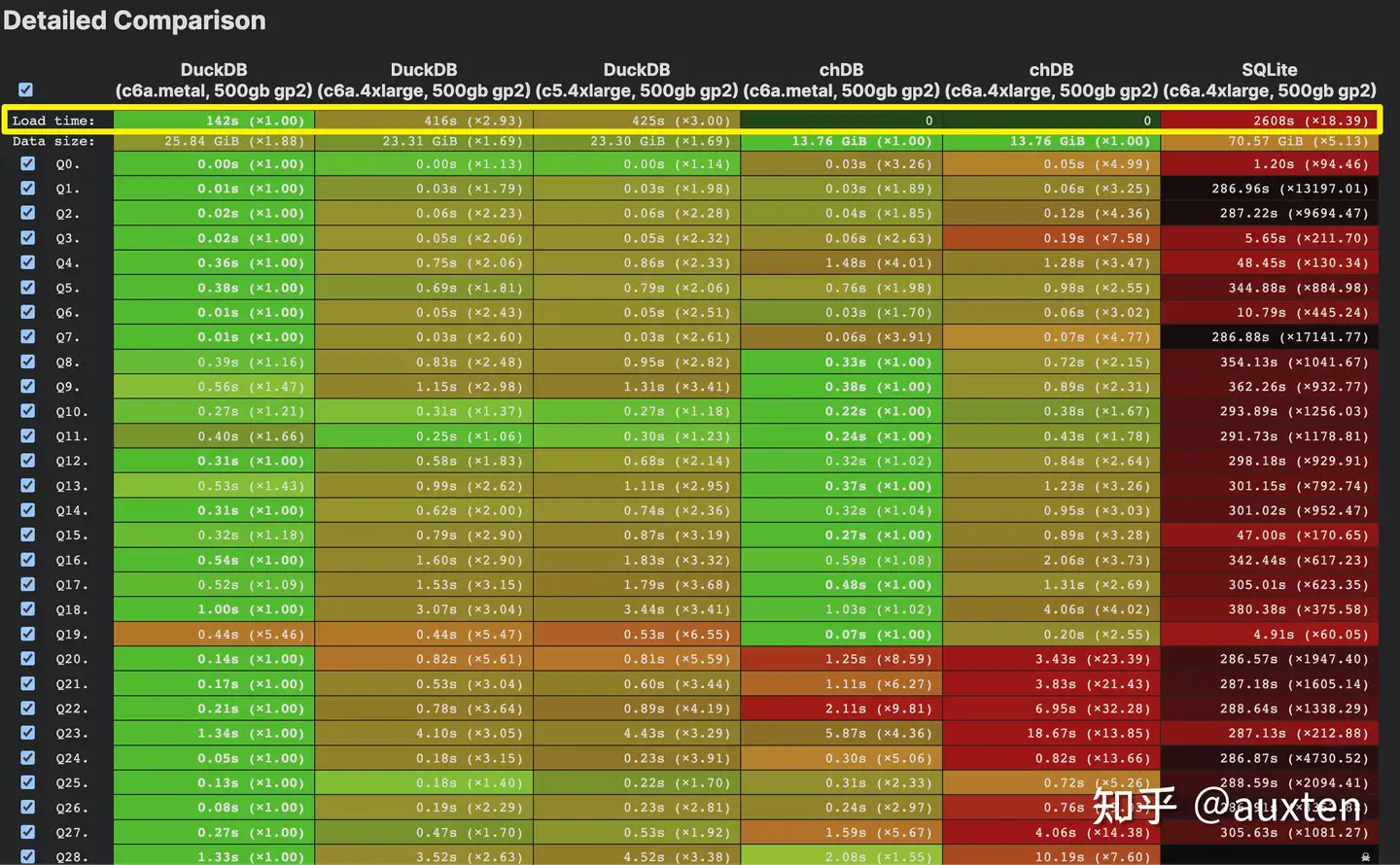
Fastest SQL on Parquet
Looking Froward
目前 chDB 正在基于最新的 ClickHouse 23.6 进行重构,预期这个版本稳定后会在 Parquet 上的性能表现有所提升。我们也在和 ClickHouse team 在以下领域密切的合作:
- 尽可能的减小 chDB 整个安装包的大小(目前压缩后在 100MB 左右,我们希望能在今年减肥到 80MB)
- 支持 Python 写 chDB 的 UDF、UDAF
- chDB 已经支持了 Pandas Dataframe 作为输入和输出,我们会持续优化这部分的性能
欢迎大家使用 chDB,也欢迎大家在 GitHub 上给我们一个 Star ⭐️
在这里感谢 ClickHouse CTO @Alexey 和 Product Head @Tanya 的支持和鼓励,没有你们的帮助就没有今天的 chDB!
目前 http://chdb.io 已经有了 10 个 projects,所有的人都是 ClickHouse 的忠实 Fans,我们是一群“用爱发电”的 Hacker!我们的目标是世界上功能最强大、性能最好的 Embedded Database!